Die Migration zu 400G/800G: Teil I
Die Planung, um zukünftige Herausforderungen in Rechenzentren zu meistern, beginnt heute. Die Ethernet-Roadmap erklärt.
Die Rechenzentrumslandschaft ändert sich wieder einmal.
Die Beschleunigung der Einführung von Cloud-Infrastruktur und -Services führt zu einem höheren Bedarf an Bandbreite, schnelleren Geschwindigkeiten und geringerer Latenzleistung. Fortschritte in der Switch- und Servertechnologie erzwingen Änderungen bei Verkabelung und Architekturen. Unabhängig vom Markt oder Schwerpunkt Ihrer Einrichtung müssen Sie die Änderungen in Ihrer Unternehmens- oder Cloud-Architektur berücksichtigen, die wahrscheinlich erforderlich sein werden, um die neuen Anforderungen zu unterstützen. Das bedeutet, dass Sie die Trends verstehen müssen, die die Einführung von Cloud-Infrastrukturen und -Services vorantreiben, sowie die neuen Infrastrukturtechnologien, mit denen Ihr Unternehmen die neuen Anforderungen erfüllen kann. Hier sind ein paar Dinge, über die Sie nachdenken sollten, wenn Sie für die Zukunft planen.
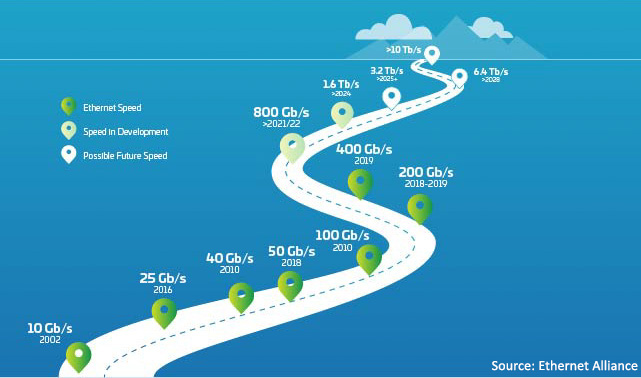
Abbildung 1: Ethernet-Roadmap
Möchten Sie offline lesen?
Laden Sie eine PDF-Version dieses Artikels herunter, um ihn später erneut zu lesen.
Bleiben Sie informiert!
Abonnieren Sie The Enterprise Source und erhalten Sie Updates, wenn neue Artikel veröffentlicht werden.
Globale Datennutzung
Im Mittelpunkt der Veränderungen stehen natürlich die globalen Trends, die die Erwartungen der Verbraucher und die Nachfrage nach mehr und schnellerer Kommunikation verändern, wie etwa:
- Explosionsartige Zunahme des Verkehrs in den sozialen Medien;
- Einführung von 5G-Diensten, ermöglicht durch massive Verdichtung von Kleinzellen;
- Beschleunigung der Bereitstellung von IoT und IIoT (Industrielles IoT);
- Verlagerung von traditioneller Büroarbeit hin zu Remote-Optionen;
Wachstum von Hyperscale-Anbietern.
Weltweit gibt es vielleicht weniger als ein Dutzend echte Hyperscale-Rechenzentren, aber ihre Auswirkungen auf die gesamten Rechenzentrumslandschaft sind enorm. Laut neuerer Forschung verbrachte die Welt insgesamt eine 1.25 Mrd. Jahre online, und das allein 2020.1Etwa 53 % dieses Datenverkehrs durchläuft ein Hyperscale-Rechenzentrum.2
Hyperscale-Partnerschaften mit Multi-Tenant-Rechenzentren (MTDC/Co-Location)
Da die Nachfrage nach einer geringeren Latenzleistung zunimmt, arbeiten Hyperscale- und Cloud-Anbieter daran, ihre Präsenz näher an den Endbenutzer bzw. das Endgerät zu bringen. Viele arbeiten mit MTDC- oder Co-Location-Rechenzentren zusammen, um ihre Dienste an der sogenannten Network Edge bereitzustellen3. Wenn sich der Edge physisch in der Nähe befindet, erhöhen geringere Latenz und Netzwerkkosten den Wert neuer Dienste mit niedriger Latenz. Infolgedessen zwingt das Wachstum im Hyperscale-Bereich Multi-Tenant-Data Center und Co-Location-Rechenzentren, ihre Infrastrukturen und Architekturen anzupassen, um die erhöhten Skalierungs- und Traffic-Anforderungen zu unterstützen, die typischer für Hyperscale-Rechenzentren sind. Gleichzeitig müssen diese größten Rechenzentren weiterhin flexibel auf Kundenanfragen nach Querverbindungen zu Cloud-Anbietern reagieren.
Spine-Leaf- und Fabric-Mesh-Netzwerke
Die Notwendigkeit, Anwendungen mit niedriger Latenz, hoher Verfügbarkeit und sehr hoher Bandbreite zu unterstützen, ist nun nicht auf Hyperscale- und Co-Location-Rechenzentren beschränkt. Alle Rechenzentren müssen jetzt ihre Fähigkeit überdenken, mit den steigenden Anforderungen von Endbenutzern und Stakeholdern umzugehen. Als Reaktion darauf bewegen sich Rechenzentrumsmanager schnell zu Mesh-Fabric-Netzwerken mit hoher Glasfaserdichte. Die All-to-All-Konnektivität, Backbone-Kabel mit höherer Glasfaseranzahl und neue Konnektivitätsoptionen ermöglichen es Netzwerkbetreibern, immer höhere Geschwindigkeiten zu unterstützen, während sie sich auf den Übergang zu 400 Gigabits pro Sekunde4(G) vorbereiten.
Ermöglichung von maschinellem Lernen (ML) und künstlicher Intelligenz (KI)
Darüber hinaus wenden sich die größeren Rechenzentrumsanbieter, die zum Teil von IoT- und Smart-City-Anwendungen angetrieben werden, KI und ML zu, um die Datenmodelle zu erstellen und zu verfeinern, die nahezu Echtzeit-Computing-Funktionen an der Edge ermöglichen. Neben dem Potenzial, eine neue Welt von Anwendungen zu ermöglichen (denken Sie an kommerziell tragfähige selbstfahrende Autos), erfordern diese Technologien massive Datensätze, die oft als Data Lakes bezeichnet werden, und massive Rechenleistung innerhalb der Rechenzentren und eine ausreichende Infrastruktur, um die verfeinerten Modelle bei Bedarf an die Edge zu bringen.5
Zeitplanung der Umstellung auf 400G/800G
Nur weil Sie heute mit 40G oder sogar 100G laufen, wiegen Sie sich nicht in falscher Sicherheit. Wenn uns die Geschichte der Entwicklung von Rechenzentren etwas gelehrt hat, ist es, dass die Änderungsrate exponentiell zunimmt, sei es Bandbreite, Glasfaserdichte oder Lane-Geschwindigkeiten. Der Übergang zu 400G ist näher, als Sie denken. Sie sind sich nicht sicher? Addieren Sie die Anzahl der 10G-Ports (oder schnellerer), die Sie derzeit unterstützen, und stellen Sie sich vor, sie würden auf 100G aufsteigen. Sie werden feststellen, dass der Bedarf an 400G (und darüber hinaus) nicht so weit entfernt ist.
Wenn Rechenzentrumsmanager in die Zukunft blicken, sehen Sie überall eine Evolution cloudbasierter Lösungen.
Mehr
virtualisierte Hochleistungsserver
Höhere
Bandbreite und geringere Latenz
Schnellere
Switch-to-Server-Verbindungen
Höhere
Uplink-/Backbone-Geschwindigkeiten
Schnelle
Erweiterungs-
möglichkeiten
In der Cloud selbst ändert sich die Hardware. Mehrere unterschiedliche Netzwerke, die typisch für alte Rechenzentren sind, haben sich zu einer virtualisierten Umgebung entwickelt, die gepoolte Hardwareressourcen und softwaregesteuertes Management verwendet. Diese Virtualisierung führt dazu, dass Anwendungszugriff und -aktivität schnellstmöglich geroutet werden müssen. Viele Netzwerkmanager fragen sich daher, wie man eine Infrastruktur entwickelt, um Cloud-First-Anwendungen zu unterstützen.
Eine erste Antwort ist, höhere Geschwindigkeiten pro Lane zu ermöglichen. Der Übergang von 25 zu 50 zu 100G und höher ist der Schlüssel zu 400G und darüber hinaus und hat begonnen, den traditionellen 1/10G-Migrationspfad zu ersetzen. Aber es gibt noch mehr als die Erhöhung der Lane-Geschwindigkeiten, viel mehr. Wir müssen etwas tiefer graben.
Die Branche erreicht einen Wendepunkt. Die Übernahme von 400G hat sehr schnell zugenommen, aber in Kürze wird erwartet, dass 800G noch schneller als 400G ansteigen wird. Es gibt keine einfache Antwort darauf, wer oder was den Übergang zu 400G antreibt, aber das stand zu erwarten. Es gibt eine Vielzahl von Faktoren, von denen viele miteinander verflochten sind. Neue Technologien ermöglichen niedrigere Kosten pro Bit, wenn die Lane-Raten steigen. Die neuesten Daten gehen davon aus, dass die 100G-Lane-Raten mit Octal Switch Ports kombiniert werden, um 800G-Optionen ab 2022 auf den Markt zu bringen. Diese Ports werden jedoch auf verschiedene Weise verwendet, wie in den Light Counting-Daten6 veranschaulicht, bei denen 400G und 800G hauptsächlich auf 4X oder 8X 100G aufgeschlüsselt sind. Diese Breakout-Anwendung ist der frühe Treiber dieser neuen optischen Anwendungen.
Abbildung 2: Ethernet-Port-Lieferungen für Rechenzentren
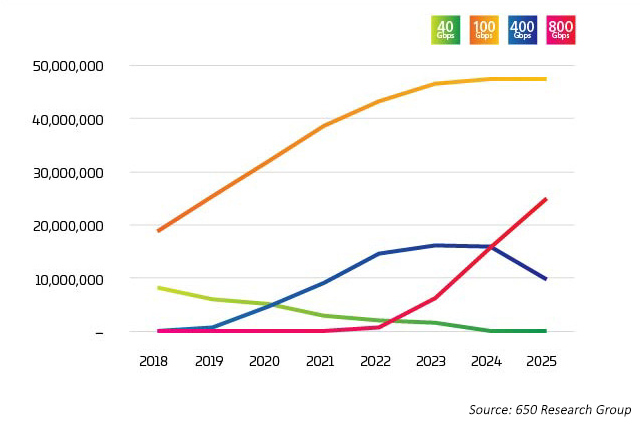
Im Datennetzwerk ist Kapazität eine Frage der gegenseitigen Kontrolle zwischen Servern, Switches und Konnektivität. Jede Komponente treibt die anderen dazu, schneller und kostengünstiger zu sein, um die Nachfrage, die durch erhöhte Datensätze, KI und ML entsteht, effizient nachzuverfolgen. Jahrelang war die Switch-Technologie der größte Engpass. Mit der Einführung von StrataXGS® Tomahawk® 3 von Broadcom können Rechenzentrumsmanager jetzt die Switching- und Routing-Geschwindigkeiten auf 12.8 Terabits/s (Tb/s) erhöhen und ihre Kosten pro Port um 75 % senken. Der Tomahawk 4 Switch Chip von Broadcom mit einer Bandbreite von 25 Tb/s bietet der Rechenzentrumsbranche mehr Switching-Fähigkeiten, um den steigenden KI- und ML-Workloads einen Schritt voraus zu sein. Heute unterstützt dieser Chip 64x 400G-Ports. Aber mit einer Kapazität von 25,6 Tb/s führt uns die Halbleitertechnologie auf einen Weg, wo sich in Zukunft 32x 800G-Ports auf einem einzigen Chip befinden könnten. 32Zufällig ist dies die maximale Anzahl von QSFP-DD oder OSFP (800G-Transceiver), die auf eine 1U Switch Faceplate passen.
Der limitierende Faktor ist also die CPU-Verarbeitungsfähigkeit. Richtig? Falsch. Anfang diesen Jahres stellte NVIDIA seinen neuen Ampere-Chip für Server vor. Es hat sich herausgestellt, dass die im Gaming verwendeten Prozessoren perfekt für das Training und die inferenzbasierte Verarbeitung geeignet sind, die für KI und ML erforderlich sind. Laut NVIDIA kann ein Ampere-basierte Rechner die Arbeit von 120 Intel-gestützten Servern erledigen.
Abbildung 3: Ethernet-Geschwindigkeiten
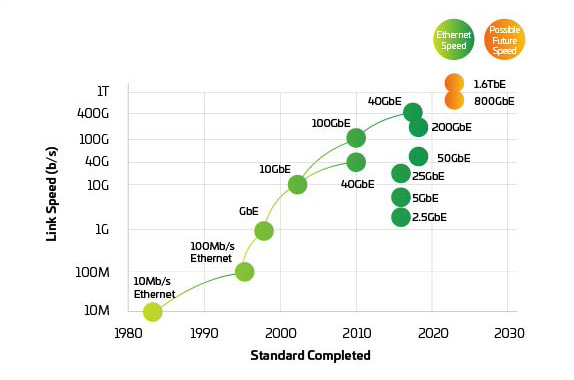
Da Switches und Server sich dahin entwickeln, dass sie 400G und 800G unterstützen, verlagert sich der Druck auf die physische Schicht, um das Netzwerk im Gleichgewicht zu halten. IEEE 802.3bs, zugelassen 2017, ebnete den Weg für das 200G- und 400G-Ethernet. Allerdings hat das IEEE gerade seine Bandbreitenbewertung bezüglich 800G und darüber hinaus abgeschlossen. Das IEEE hat eine Studiengruppe gegründet, um die Ziele für Anwendungen über 400G hinaus zu identifizieren, und angesichts der Zeit, die für die Entwicklung und Einführung neuer Standards erforderlich ist, könnten wir bereits hinterherfallen. Die Branche arbeitet jetzt zusammen, um 800G einzuführen und auf 1.6 T und mehr hinzuarbeiten, während sie gleichzeitig die Leistung und die Kosten pro Bit verbessert.
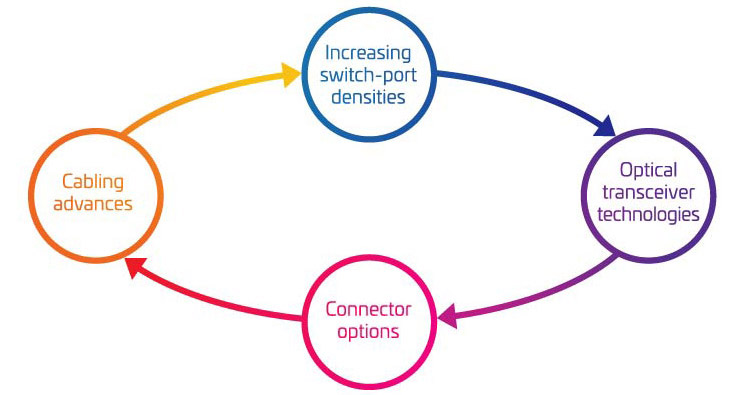
Die vier Säulen der Migration von 400G/800G
Wenn Sie die praktischen Grundlagen der Unterstützung Ihrer Migration zu 400G in Betracht ziehen, ist es leicht, von der Komplexität überfordert zu werden. Um Ihnen zu helfen, die wichtigsten Variablen, die berücksichtigt werden müssen, besser zu verstehen, haben wir sie in vier Hauptbereiche gruppiert:
- Zunehmende Dichte der Switch-Ports
- Optische Transceiver-Technologien
- Steckeroptionen
- Verkabelungsfortschritte
Zusammen stellen diese vier Bereiche einen großen Teil Ihrer Toolbox für die Migration dar. Verwenden Sie sie, um Ihre Migrationsstrategie auf Ihre aktuellen und zukünftigen Bedürfnisse abzustimmen.
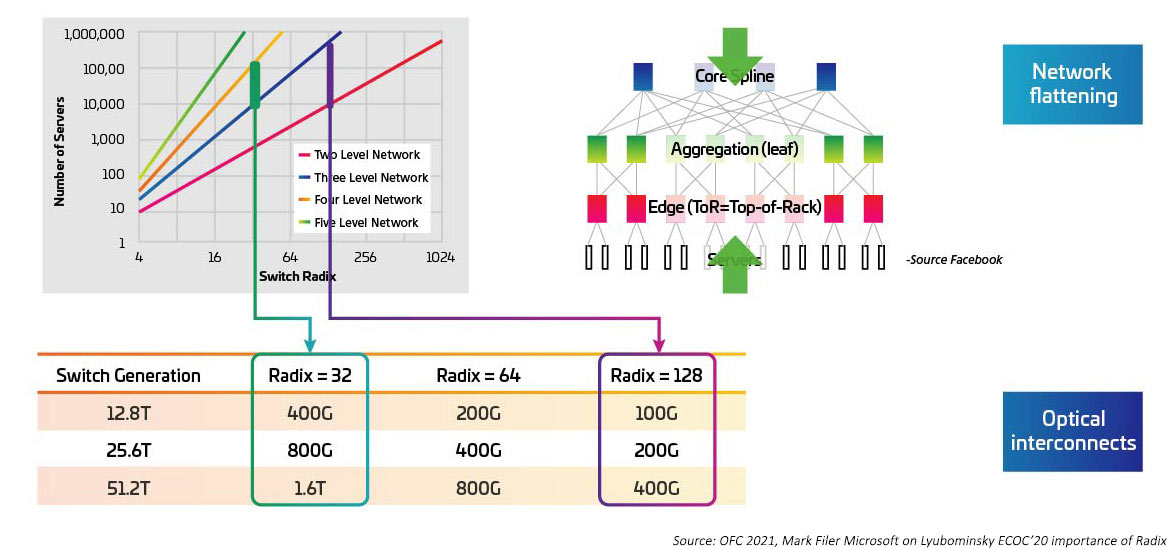
Die Schaltgeschwindigkeiten steigen, da die Serialisierer/Deserialisierer (SERDES), die elektrisches E/A für die Switching ASIC bereitstellen, von 10G zu 25G und 50G wechseln. Es wird erwartet, dass SERDES 100G erreichen, sobald IEEE802.3ck zu einem ratifizierten Standard wird. Die anwendungsspezifischen integrierten Schaltkreise (ASICs) erhöhen ebenfalls die Dichte des E/A-Ports (auch Radix genannt). Höhere Radix-ASICs unterstützen mehr Netzwerkgeräteverbindungen und bieten das Potenzial, Layer-Top-of-Rack-Switches (ToR) zu eliminieren. Dies wiederum reduziert die Gesamtzahl der Switches, die für ein Cloud-Netzwerk benötigt werden. (Ein Rechenzentrum mit 100,000 Servern kann mit einem RADIX von 512 auf zwei Ebenen umgeschaltet werden.) Die ASICs mit höherem Radix bedeuten niedrigere Investitionsausgaben (weniger Switches), niedrigere Betriebskosten (weniger Energie für die Stromversorgung und Kühlung weniger Switches) und verbesserte Netzwerkleistung durch geringere Latenzzeiten.
Abbildung 4: Auswirkungen höherer Radix-Switches auf die Switch-Bandbreite
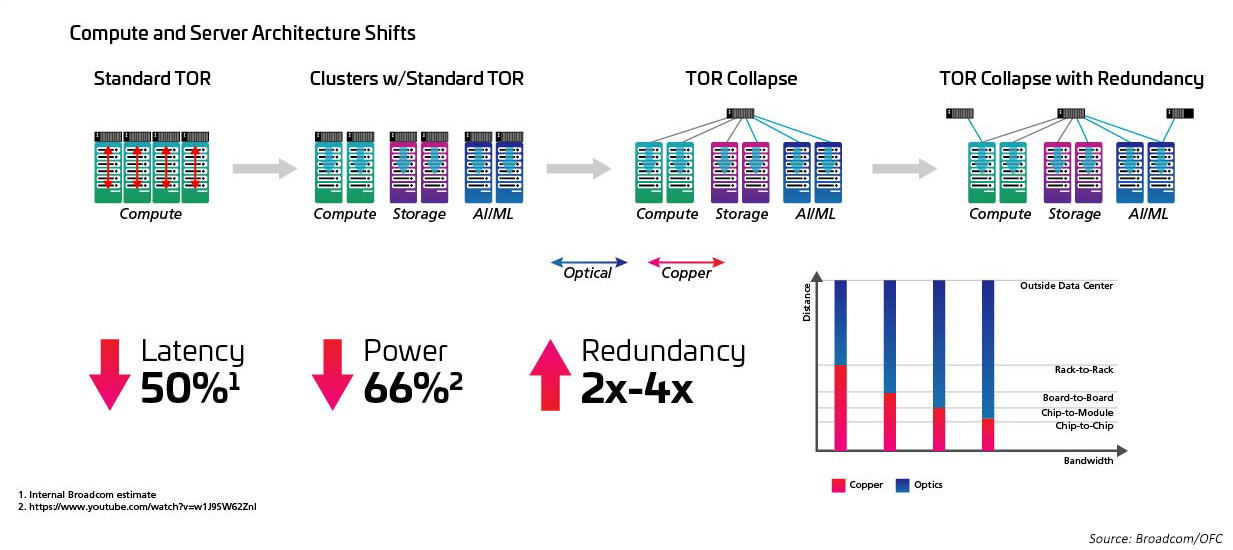
Eng verbunden mit dem Anstieg der Radix- und Schaltgeschwindigkeit ist der Wechsel von einer ToR-Topologie (Top-of-Rack) zu einer MoR-Konfiguration (Middle-of-Row) oder EoR-Konfiguration (End-of-Row) und der Vorteil, den der strukturierte Verkabelungsansatz bietet, wenn die vielen Verbindungen zwischen den In-Row-Servern und den MoR/EoR-Switches erleichtert werden. Die Fähigkeit, die große Anzahl an Serververbindungen effizienter zu verwalten, ist erforderlich, um neue High-Radix-Switches zu nutzen. Dies wiederum erfordert neue optische Module und strukturierte Verkabelungen, wie sie in der Norm IEEE802.3cm definiert sind. Der IEEE802.3cm-Standard unterstützt die Vorteile steckbarer Transceiver zur Verwendung mit HS-Server-Netzwerkanwendungen in großen Rechenzentren, die acht Host-Anhänge zu einem QSFP-DD-Transceiver definieren.
Abbildung 5: Architekturen wechseln von ToR zu MoR/EoR
Genauso wie die Einführung des QSFP28-Formfaktors die Einführung von 100G durch hohe Dichte und geringeren Stromverbrauch vorangetrieben hat, wird der Sprung zu 400G und 800G durch neue Transceiver-Formfaktoren ermöglicht. Die aktuelle SFP-, SFP+- oder QSFP+-Optik reicht aus, um 200G-Verbindungsgeschwindigkeiten zu ermöglichen. Der Sprung zu 400G erfordert jedoch die Verdoppelung der Dichte der Transceiver. Kein Problem.
QSFP-Double Density (QSFP-DD7) und oktale (2-Mal pro Quadrat) Small Form Factor Pluggable (OSFP8) Multi Source Agreements (MSAs) ermöglichen Netzwerken die Verdoppelung der Anzahl der elektrischen E/A-Verbindungen zum ASIC. Dadurch können nicht nur mehr E/A summiert werden, um höhere Gesamtgeschwindigkeiten zu erreichen. Die Gesamtzahl der ASIC-E/A-Verbindungen kann auch das Netzwerk zu erreichen.
Der 1U-Switch-Formfaktor mit 32 QSFP-DD-Ports stimmt mit 256 den (32x8) ASIC-E/A überein. Auf diese Weise können wir Hochgeschwindigkeitsverbindungen zwischen Switches (8*100 oder 800G) aufbauen, aber auch die maximale Anzahl an Verbindungen beim Anschließen von Servern beibehalten.
Neue Transceiver-Formate
Der optische Markt für 400G wird durch Kosten und Leistung angetrieben, da OEMs versuchen, die perfekte Position zwischen Hyperscale- und Cloud-Scale-Rechenzentren zu finden. 2017 wurde CFP8 zum 400G-Modulformfaktor der ersten Generation, der in Core-Routern und DWDM-Transport-Client-Schnittstellen verwendet wurde. Der CFP8-Transceiver war der vom CFP-MSA angegebene 400G-Formfaktortyp. Die Modulabmessungen sind etwas kleiner als CFP2, während die Optik entweder CDAUI-16 (16x25G NRZ) oder CDAUI-8 (8x50G PAM4) elektrische E/A unterstützt. Was die Bandbreitendichte betrifft, so unterstützt sie jeweils das Achtfache und Vierfache der Bandbreitendichte von CFP- und CFP2-Transceivern.
Die 400G-Formfaktormodule der zweiten Generation sind mit QSFP-DD und OSFP ausgestattet. Die QSFP-DD-Transceiver sind mit vorhandenen QSFP-Ports abwärtskompatibel. Sie bauen auf dem Erfolg der vorhandenen Optikmodule QSFP+ (40G), QSFP28 (100G) und QSFP56 (200G) auf.
OSFP ermöglicht, wie die QSFP-DD-Optik, die Verwendung von acht Bahnen gegenüber vier Lanes. Beide Modultypen unterstützen 32 Ports in einer 1RU-Karte (Switch). Um die Abwärtskompatibilität zu unterstützen, benötigt das OSFP einen OSFP-zu-QSFP-Adapter.
Abbildung 6: OSFP vs. QSFP-DD-Transceiver

Modulationsschemata
Netzwerkingenieure nutzen seit langem die NRZ-Modulation (Non-Return to Zero) für 1G, 10G und 25G unter Verwendung der hostseitigen FEC (Forwared Error Correction), um Übertragungen über größere Entfernungen zu ermöglichen. Um von 40G auf 100G zu kommen, wandte sich die Branche einfach der Parallelisierung der 10G/25G NRZ-Modulationen zu und nutzte auch die hostseitige FEC für längere Entfernungen. Wenn es darum geht, Geschwindigkeiten von 200G/400 G und schneller zu erreichen, sind neue Lösungen erforderlich.
Abbildung 7: Hochgeschwindigkeitsmodulationsschemata werden verwendet, um 50G- und 100G-Technologien zu ermöglichen
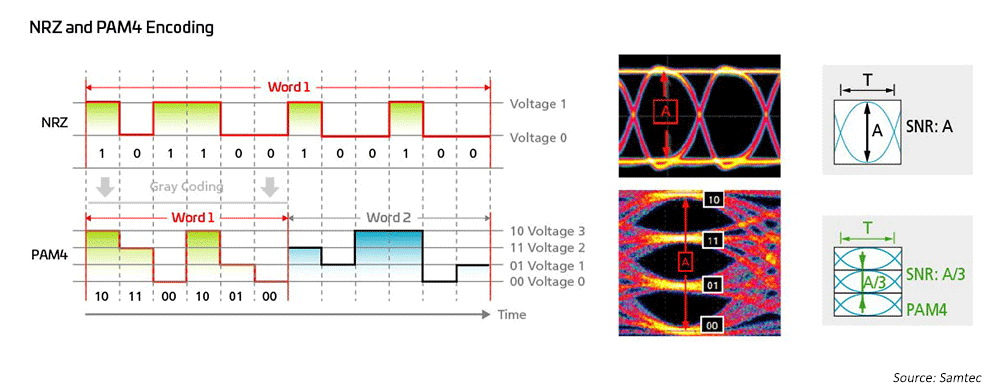
Infolgedessen haben sich Ingenieure, die an optischen Netzwerken arbeiten, sich der vierstufigen Pulsamplitudenmodulation (PAM4) zugewandt, um Netzwerkarchitekturen mit ultrahoher Bandbreite zu realisieren. PAM4 ist die aktuelle Lösung für 400GPAM4. Dies basiert in großem Umfang auf IEEE802.3, das neue Ethernet-Standards für Raten von bis zu 400G (802,3bs/cd/cu) für MM- und SM-Anwendungen (Multi-Mode und Single-Mode) eingeführt hat. Es stehen eine Vielzahl von Breakout-Optionen zur Verfügung, um verschiedene Netzwerktopologien in großen Rechenzentren zu berücksichtigen.
Komplexere Modulationsschemata implizieren die Notwendigkeit einer Infrastruktur, die eine bessere Rückflussdämpfung bieten kann.
Vorhersagen: OSFP vs. QSFP-DD
In Bezug auf OSFP im Vergleich zu QSFP-DD ist es noch zu früh, um zu sagen, welchen Weg die Branche einschlagen wird. Beide Formfaktoren werden von führenden Ethernet-Switch-Anbietern für Rechenzentren unterstützt und beide haben einen großen Kundensupport. Vielleicht wird das Unternehmen QSFP-DD als Verbesserung der aktuellen QSFP-basierten Optik bevorzugen. OSFP scheint mit der Einführung von OSFP-XD neue Möglichkeiten aufzuzeigen und die Anzahl der Lanes mit Blick auf die zukünftigen 200G-Lane-Raten auf 16 zu erweitern.
Für Geschwindigkeiten von bis zu 100G hat sich QSFP aufgrund seiner Größe, Leistung und Kostenvorteile im Vergleich zu Duplex-Transceivern zu einer bevorzugten Lösung entwickelt. QSFP-DD baut auf diesem Erfolg auf und bietet eine Abwärtskompatibilität, die die Verwendung von QSFP-Transceivern in einem Switch mit der neuen DD-Schnittstelle ermöglicht.
Viele glauben, dass die 100G QSFP-DD-Stellfläche auch in Zukunft beliebt sein wird. Die OSFP-Technologie kann für optische DCI-Verbindungen oder solche bevorzugt werden, die insbesondere höhere Leistung und mehr optische E/A erfordern. Befürworter von OSFP sehen in Zukunft 1.6T- und vielleicht sogar 3.2T-Transceiver.

Co-Packaged Optics (CPOs) bieten einen alternativen Weg zu 1.6 T und 3.2 T. CPOs benötigen jedoch ein neues Ökosystem, das die Optik näher an die Switch-ASICs bringt, um die höheren Geschwindigkeiten zu erreichen und gleichzeitig den Stromverbrauch zu senken. An diesem Weg wird im Optical Internetworking Forum (OIF) gearbeitet. Das OIF diskutiert nun die Technologien, die sich am besten für die nächste Rate eignen könnten, wobei viele für eine Verdoppelung auf 200G argumentieren. Weitere Optionen sind mehr Lanes – vielleicht 32, da einige glauben, dass mehr Lanes und höhere Lane-Raten letztendlich erforderlich sein werden, um mit der Netzwerknachfrage zu erschwinglichen Netzwerkkosten Schritt zu halten.
Die einzige sichere Vorhersage ist, dass die Verkabelungsinfrastruktur über die integrierte Flexibilität verfügen muss, um Ihre zukünftigen Netzwerktopologien und Linkanforderungen zu unterstützen. Während Astronomen seit langem der Ansicht sind, dass jedes Photon zählt, versuchen Netzwerkdesigner, die Energie pro Bit auf ein paar pJ/Bit zu reduzieren9. Die Konservierung ist auf jeder Ebene wichtig. Die leistungsstarke Verkabelung trägt dazu bei, den Netzwerkbetriebskosten zu reduzieren.
Switches entwickeln sich weiter, um mehr Lanes bei höheren Geschwindigkeiten bereitzustellen und gleichzeitig die Kosten und den Stromverbrauch von Netzwerken zu reduzieren. Oktalmodule ermöglichen die Verbindung dieser zusätzlichen Anschlüsse über 1U-Switches, die Platz für 32 Ports bieten. Die Aufrechterhaltung des höheren Radix wird durch die Verwendung des Lane Breakouts vom Optikmodul erreicht.
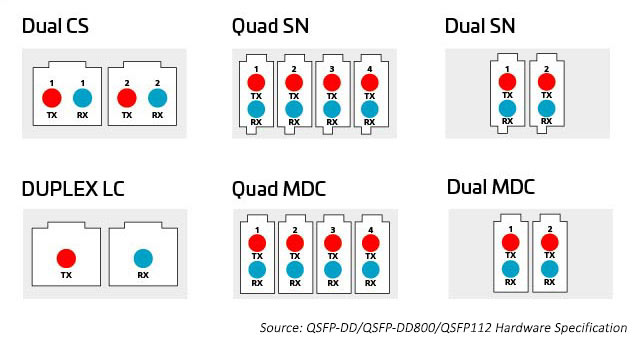
Die Vielzahl der Anschlusstechnologieoptionen bietet mehr Möglichkeiten, die zusätzliche Kapazität, die Oktalmodule bieten, aufzuschlüsseln und zu verteilen. Zu den Anschlüssen gehören parallele 8-, 12-, 16- und 24-Faser-Multi-Push-On- (MPO) ) sowie Duplex-Glasfaser-LC-, SN-, MDC- und CS-Anschlüsse. Weitere Informationen finden Sie unten.
Abbildung 8: Optionen zur Verteilung der Kapazität von Oktalmodulen
MPO-Kupplungen
Bis vor kurzem umfasste die primäre Methode zur Verbindung von Switches und Servern innerhalb des Rechenzentrums eine Verkabelung, die um 12- oder 24-Fasern organisiert war, typischerweise mit MPO-Kupplungen. Durch die Einführung der Oktaltechnologie (acht Switch Lanes pro Switch Port) können Rechenzentren die erhöhte Anzahl an ASIC I/Os (derzeit 256 pro Switch ASIC) mit optischen Ports abgleichen. Dies ergibt die maximale Anzahl an E/A, die für die Verbindung von Servern oder anderen Geräten verfügbar sind.
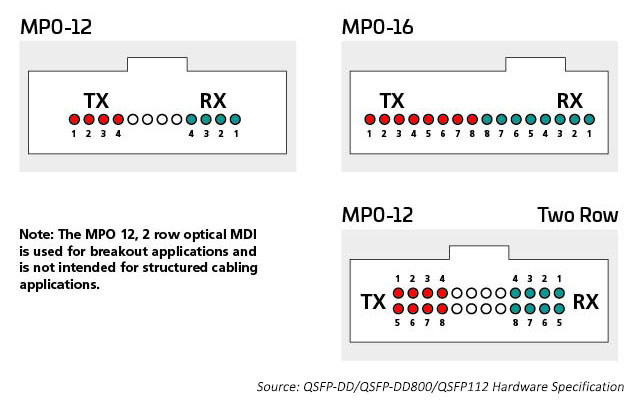
Die optischen E/A verwenden Anschlüsse, die für die Anzahl der verwendeten optischen Lanes geeignet sind. Ein 400G-Transceiver kann einen einzelnen Duplex-LC-Anschluss mit einem optischen 400G-E/A aufweisen. Er könnte jedoch auch 4 X optische 100G-E/A haben, die 8 Glasfaserleitungen erfordern. Die MPO12- oder vielleicht 4 SN-Duplexsteckverbinder passen in das Transceiver-Gehäuse und versorgen die 8 Glasfasern, die diese Anwendung benötigt. Sechzehn Glasfasern sind erforderlich, um 8 elektrischen und optischen E/A zu entsprechen und die Radix des Switch ASIC zu erhalten. Es können optische Single-Mode- oder Multi-Mode-Ports eingesetzt werden, abhängig von der Entfernung.
Beispielsweise bietet die Multimodus-Technologie weiterhin die kostengünstigsten optischen Hochgeschwindigkeitsdatenraten für Verbindungen mit kurzer Reichweite im Rechenzentrum. IEEE-Standards unterstützen 400G in einer Single-Link-Technologie (802.3 400G SR4.2), die vier Glasfasern zum Übertragen und vier Glasfaser zum Empfangen verwendet, wobei jede Glasfaser zwei Wellenlängen trägt. Dieser Standard erweitert den Einsatz von bidirektionalen Wellenlängenmultiplexverfahren (BiDi WDM) und wurde ursprünglich zur Unterstützung von Switch-to-Switch-Verbindungen entwickelt. Dieser Standard verwendet den MPO12-Anschluss und war der erste, der mit OM5 MMF optimiert wurde.
Die Aufrechterhaltung des Switch-Radix ist wichtig, wenn viele Geräte wie Serverracks mit dem Netzwerk verbunden werden müssen. 400G SR8, adressiert im IEEE 802.3cm Standard (2020), unterstützt acht Serververbindungen mit acht Glasfasern zum Übertragen und acht Glasfasern zum Empfangen. Diese Anwendung wird von Cloud-Betreibern anerkannt. Zur Optimierung dieser Lösung werden MPO-16-Architekturen eingesetzt.
Single-Mode-Standards unterstützen Anwendungen mit größerer Reichweite (z. B. Switch-to-Switch). IEEE 400G-DR4 unterstützt 500 Messgeräte mit 8 Glasfasern. Diese Anwendung kann von MPO-12 oder MPO-16 unterstützt werden. Der Wert des 16-Glasfaser-Ansatzes ist zusätzliche Flexibilität; Rechenzentrumsmanager können einen 400G-Schaltkreis in überschaubare 50/100-G-Verbindungen aufteilen. Beispielsweise kann eine 16-Glasaser-Verbindung am Switch unterbrochen werden, um bis zu acht Server zu unterstützen, die sich bei 50/100G verbinden und gleichzeitig die elektrische Lane Rate anpassen. MPO 16-Glasfaser-Anschlüsse sind unterschiedlich verschlüsselt, um eine Verbindung mit den 12-Faser-MPO-Anschlüssen zu verhindern.
Die elektrische Lane Rate bestimmt dann die Ausgabefähigkeiten der optischen Schnittstelle. Tabelle 1 zeigt Beispiele für die Standards bzw. Möglichkeiten des Moduls 400G (50G X 8).
Tabelle 1: 400G Kapazität QSFP-DD mit 50G elektrischen Lanes
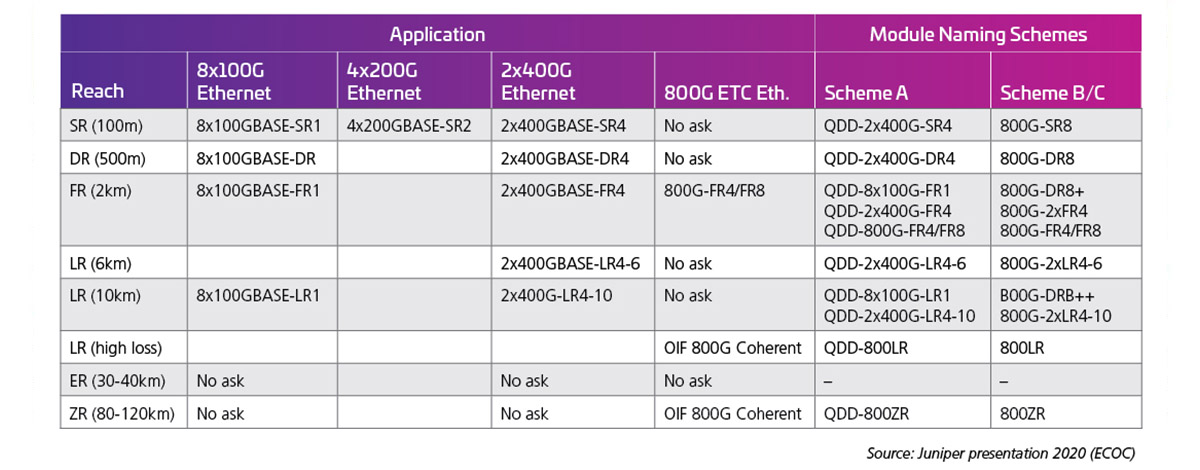
Bei Verdoppelung der Lane Rates auf 100G werden folgende optische Schnittstellen möglich. Zum Zeitpunkt des Verfassens wurden die 100G-Standards für die Lane Rate (802.3 ck) noch nicht abgeschlossen; allerdings werden frühe Produkte veröffentlicht und viele dieser Optionen sind bereits auf dem Weg zum Kunden. Tabelle 2, präsentiert beim ECOC 2020 von J. Maki (Juniper), zeigt das frühe Brancheninteresse an den 800G-Modulen.
Tabelle 2: 800G Kapazität QSFP-DD mit 100G elektrischen Lanes
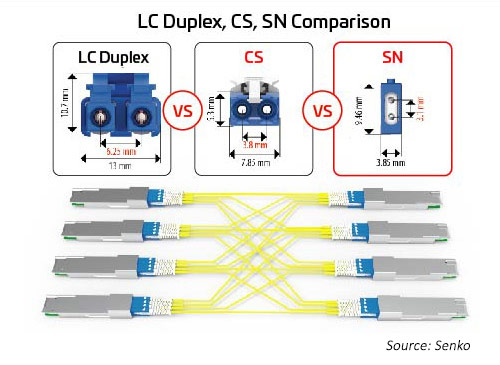
Duplex-Anschlüsse
Mit zunehmender Anzahl von Lanes und Lane-Geschwindigkeiten wird die Aufteilung der optischen E/A attraktiver. Wie bereits erwähnt, können Oktalmodule Anschlussoptionen für 1, 2, 4 oder 8 Duplex Links unterstützen. Alle diese Optionen können mit einem MPO-Anschluss untergebracht werden; diese Option ist jedoch möglicherweise nicht so effizient wie separate Duplex-Anschlüsse. Ein Duplex-Anschluss mit einer kleineren Stellfläche kann diese Optionen ermöglichen. Der SN, ein Duplex-Glasfaseranschluss mit sehr kleinem Formfaktor (VSFF), passt zu dieser Anwendung. Es verfügt über dieselbe 1,25-mm-Klemmhülse, die zuvor in den LC-Steckverbindern verwendet wurde. Infolgedessen bietet es die gleiche optische Leistung und Festigkeit, ist aber auf flexiblere Breakout-Optionen für optische Hochgeschwindigkeitsmodule ausgerichtet. Der SN-Steckverbinder kann vier Duplexverbindungen zu einem Octal Transceiver Modul bereitstellen. Die frühen SN-Anwendungen dienen hauptsächlich dazu, Breakout-Anwendungen für optische Module zu ermöglichen.
Abbildung 10: Das Größenverhältnis zwischen führenden Duplex-Anschlüssen und Breakout-Anwendungen für die Migration zu 400G/800G
Geschwindigkeitsbegrenzungen für Stecker?
Stecker geben in der Regel keine Geschwindigkeit vor, sondern die Wirtschaftlichkeit. Optische Technologien wurden ursprünglich von Dienstleistern entwickelt und eingesetzt, die über die finanziellen Mittel und Bandbreitenanforderungen verfügten, um ihre Entwicklung zu unterstützen, sowie die Langstreckenverbindungen, die wirtschaftlich am meisten mit der geringsten Anzahl an Glasfasern überbrückt werden. Heutzutage bevorzugen die meisten Serviceanbieter Simplex- oder Duplex-Anschlüsse in Kombination mit optischen Transportprotokollen, die Single-Fiber-Anschlusstechnologien wie LC oder SC verwenden.
Diese Langstreckenlösungen können jedoch zu teuer sein, insbesondere, wenn es Hunderte oder Tausende von Verbindungen und kürzere Verbindungsabstände gibt, die zu durchlaufen sind; beide Bedingungen sind typisch für ein Rechenzentrum. Daher setzen Rechenzentren häufig parallele Optiken ein. Da parallele Transceiver niedrigere Kosten pro Gigabit bieten, ist MPO-basierte Konnektivität eine gute Option über kürzere Entfernungen. Daher wird die Auswahl von Steckverbindern heutzutage nicht so stark von der Geschwindigkeit bestimmt, sondern von der Anzahl der Data Lanes, die sie unterstützen können, dem Platz, den sie einnehmen, und den Preisauswirkungen auf Transceiver und Switch-Technologien.
In der abschließenden Analyse erweitert sich das Angebot an optischen Transceivern und optischen Steckverbindern, angetrieben durch eine Vielzahl von Netzwerkdesigns. Hyperscale-Rechenzentren entscheiden sich möglicherweise für ein sehr kundenspezifisches optisches Design. Angesichts der Größe dieser Marktteilnehmer reagieren Normungsgremien und OEMs häufig mit der Entwicklung neuer Standards und Marktchancen. Infolgedessen führen Investitionen und Skalierung die Branche in neue Richtungen und Kabeldesigns, um diese neuen Anforderungen zu erfüllen.
Erfahren Sie mehr über die neuesten Kabelfortschritte. Lesen Sie Die Migration zu 400G/800G: Teil II.

Propel™ – die Hochgeschwindigkeits-Glasfaserplattform

Lösungen für Unternehmensrechenzentren

Lösung
Hyperscale- und Cloud-Rechenzentren

Lösung
Mandantenfähige Rechenzentren

Lösung
Serviceprovider-Rechenzentren

Einblicke
Multimode-Glasfaser: die Faktendatei
Ressourcen
Bibliothek der Hochgeschwindigkeitsmigration

Informationen zur Spezifikation
OSFP MSA

Informationen zur Spezifikation
QSFP-TT MSA
Spezifizierung
QSFP-DD Hardware


Auf den ersten Blick scheint das Feld potenzieller Infrastrukturpartner, die um Ihr Unternehmen kämpfen, ziemlich überfüllt zu sein. Es gibt keinen Mangel an Anbietern, die bereit sind, Ihnen Glasfasern und Konnektivität zu verkaufen. Aber wenn Sie genauer hinsehen und überlegen, was für den langfristigen Erfolg Ihres Netzwerks entscheidend ist, wird die Auswahl immer kleiner. Das liegt daran, dass mehr als Glasfaser und Konnektivität erforderlich sind, um die Entwicklung Ihres Netzwerks sehr stark voranzutreiben. Hier zeichnet sich CommScope aus.
Nachgewiesene Leistung: CommScope kann auf eine mehr als 40-jährige Innovations- und Leistungsgeschichte zurückblicken: Unsere Singlemode-Faser TeraSPEED® kam drei Jahre vor dem ersten OS2-Standard auf den Markt, und unsere bahnbrechende Breitband-Multimode-Faser war die Grundlage für OM5-Multimode. Heute unterstützen unsere End-to-End-Glasfaser- und Kupferkabellösungen und AIM-Intelligenz Ihre anspruchsvollsten Anwendungen mit der Bandbreite, den Konfigurationsoptionen und der extrem verlustarmen Leistung, die Sie benötigen, um mit Zuversicht zu wachsen.
Agilität und Anpassungsfähigkeit: Unser modulares Portfolio ermöglicht es Ihnen, schnell und einfach auf sich ändernde Anforderungen in Ihrem Netzwerk zu reagieren. Singlemode und Multimode, vorkonfektionierte Kabelkonfektionen, hochflexible Patchpanels, modulare Komponenten, 8-, 12-, 16- und 24-Glasfaser-MPO-Konnektivität, sehr kleine Duplex- und Parallelsteckverbinder. CommScope sorgt für Schnelligkeit, Agilität und genutzte Chancen.
Zukunftssicher: Bei der Migration von 100G auf 400G, 800G und darüber hinaus bietet unsere Hochgeschwindigkeits-Migrationsplattform einen klaren Weg zu höheren Glasfaserdichten, schnelleren Lane-Geschwindigkeiten und neuen Topologien. Reduzieren Sie Netzwerkebenen, ohne die Verkabelungsinfrastruktur zu ersetzen, und wechseln Sie zu Servernetzwerken mit höherer Geschwindigkeit und geringerer Latenz, wenn sich Ihre Anforderungen weiterentwickeln. Eine robuste und agile Plattform bringt Sie nach vorn.
Garantierte Zuverlässigkeit: Mit unserer Application Assurance garantiert CommScope, dass die Links, die Sie heute entwerfen, Ihre Anwendungsanforderungen über Jahre hinweg erfüllen. Wir unterstützen diese Verpflichtung mit einem ganzheitlichen Lebenszyklus-Serviceprogramm (Planung, Design, Implementierung und Betrieb), einem globalen Team von Field Application Engineers und der 25-jährigen Garantie von CommScope.
Globale Verfügbarkeit und lokaler Support: Die globale Präsenz von CommScope umfasst Fertigungs-, Vertriebs- und lokale technische Dienstleistungen auf sechs Kontinenten mit 20,000 leidenschaftlichen Fachleuten. Wir sind für Sie da, wann und wo immer Sie uns brauchen. Unser globales Partnernetzwerk stellt sicher, dass Sie über die zertifizierten Designer, Installateure und Integratoren verfügen, um Ihr Netzwerk voranzubringen.





1 Digital Trends 2020; thenextweb.com
2 The Golden Age of HyperScale; Data Centre magazine; 30. November 2020
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5 The Datacenter as a Computer Designing Warehouse-Scale Machines Third Edition Luiz André Barroso, Urs Hölzle und Parthasarathy Ranganathan Google LLC. Morgan & Claypool publishers pg 27
6 LightCounting Präsentation für die ARPA-E Conference – Oktober 2019.pdf (energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9 Andy Bechtolsheim, Arista, OFC '21
Die Umstellung auf 400Gb passiert früher als Sie denken
Hier finden Sie eine Übersicht über die Anzeichen, die auf die Cloud-basierte DC-Entwicklung hinweisen.